Category: Blog
-

The Hidden Cost of Tier 1 Triage (And Why Hiring Won’t Fix It) Every CFO has approved the same headcount request: “We need two more support engineers to handle the load.” Then six months later, the same request comes back. Here’s why hiring is the wrong lever — and what to do instead. By Shawn…
-

Your Support Team Isn’t Broken — It’s Drowning Industry data shows 60–70% of support tickets aren’t actually problems. They’re knowledge base questions, incomplete reports, false alarms, and duplicates. Your six-figure engineers are spending 2–3 hours a day on triage work that shouldn’t require their skills. Here’s the math. By Shawn Ennis•June 1, 2026•5 min read…
-

By Shawn Ennis | Rapax I have been on both sides of the OSS/BSS procurement table. I know how these conversations go. The vendor demo looks right. The reference calls are positive. The contract gets signed. The implementation begins. And six months later, the scope has drifted, the timeline has slipped, and the operator is…
-

By Shawn Ennis | Rapax There is a number that every VP of Engineering knows intuitively but almost nobody has written down as a single figure: the number of integration paths their environment requires. Here is the math. If you are running five OSS/BSS platforms with full cross-integration, you have up to twenty potential integration…
-

By Shawn Ennis | Rapax You already know which tools you want to eliminate. You signed those contracts five, ten, maybe fifteen years ago. They made sense at the time. A fault management system from one era. A performance management platform from another. A ticketing integration built by a systems integrator who is no longer…
-

Every carrier I have talked to in the last five years has more data than they have ever had. Telemetry from every device on the network, every interface, every optical span, every customer premise. SNMP traps, syslog streams, NETCONF notifications, API feeds from every platform in the OSS/BSS stack. Petabytes of operational data, accumulating around…
-

There is a category of financial loss that does not show up on a damage report, does not generate an incident ticket, and does not appear on anyone’s weekly ops review. It is not a security breach. It is not a billing fraud. It is not a customer dispute that your team is aware of…
-
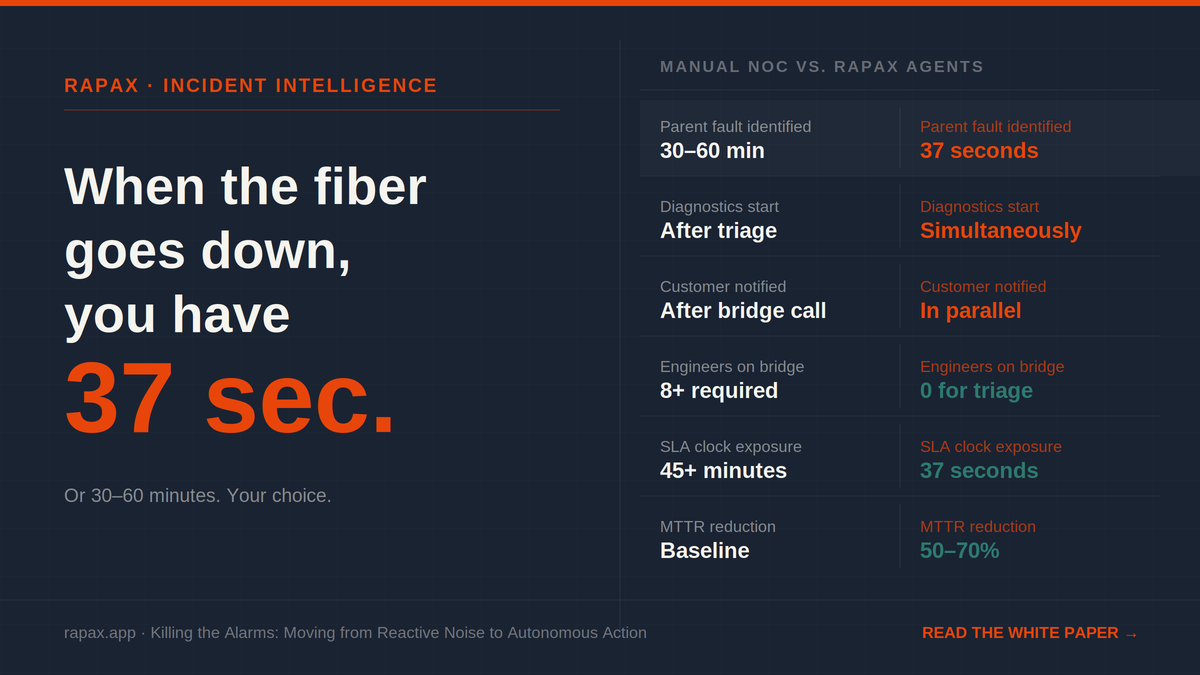
You know the call. Every VP of Operations and CTO in telecom knows the call. It comes in on a Saturday morning, or at 2 a.m. on a Tuesday, or in the middle of a board presentation. The fiber is down. A node is unreachable. Alarms are cascading across the dashboard faster than anyone can…
-
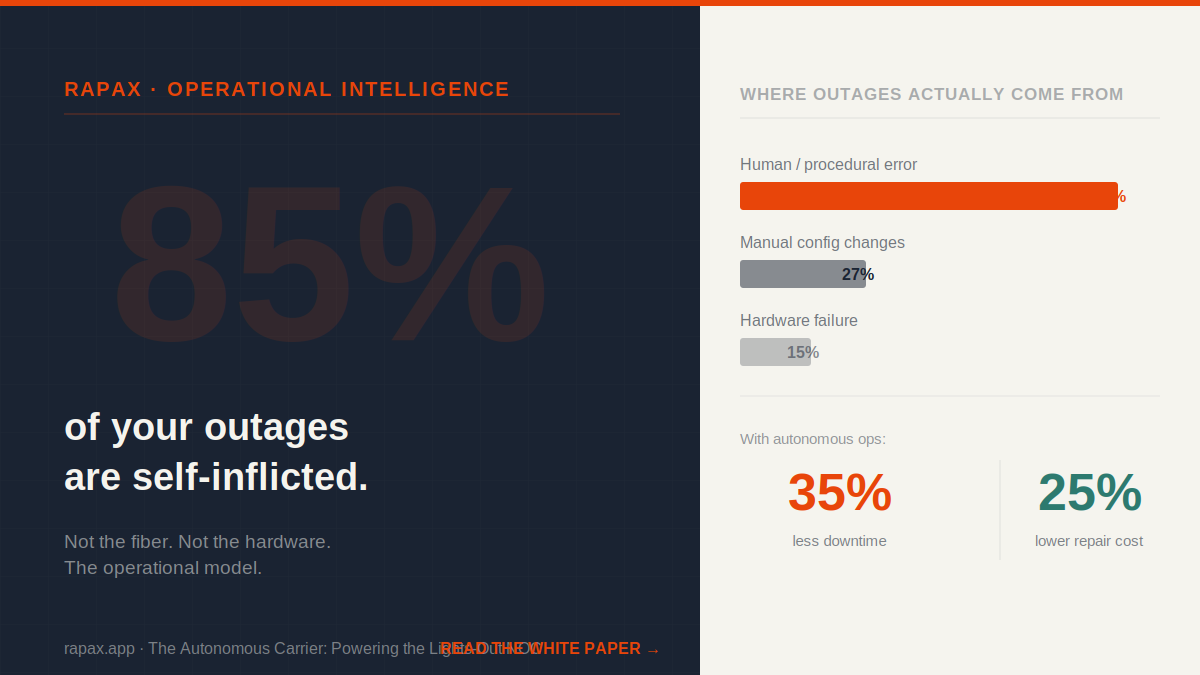
That number deserves a moment to land. Not 85% of minor incidents. Not 85% of the low-severity events that close themselves in ten minutes. Eighty-five percent of human-error-related network outages — the ones that trigger bridge calls, SLA penalties, customer complaints, and emergency overtime — are caused by staff failing to follow or misinterpreting complex…
-

Think about the last time you looked at your NOC team’s actual workload — not the job descriptions, not the org chart, but what they spent their hours doing last Tuesday. Alarm triage. Ticket routing. Configuration verification. Scheduled health checks. Escalation bridges for events that turned out to be nothing. Manual correlation of fault data…