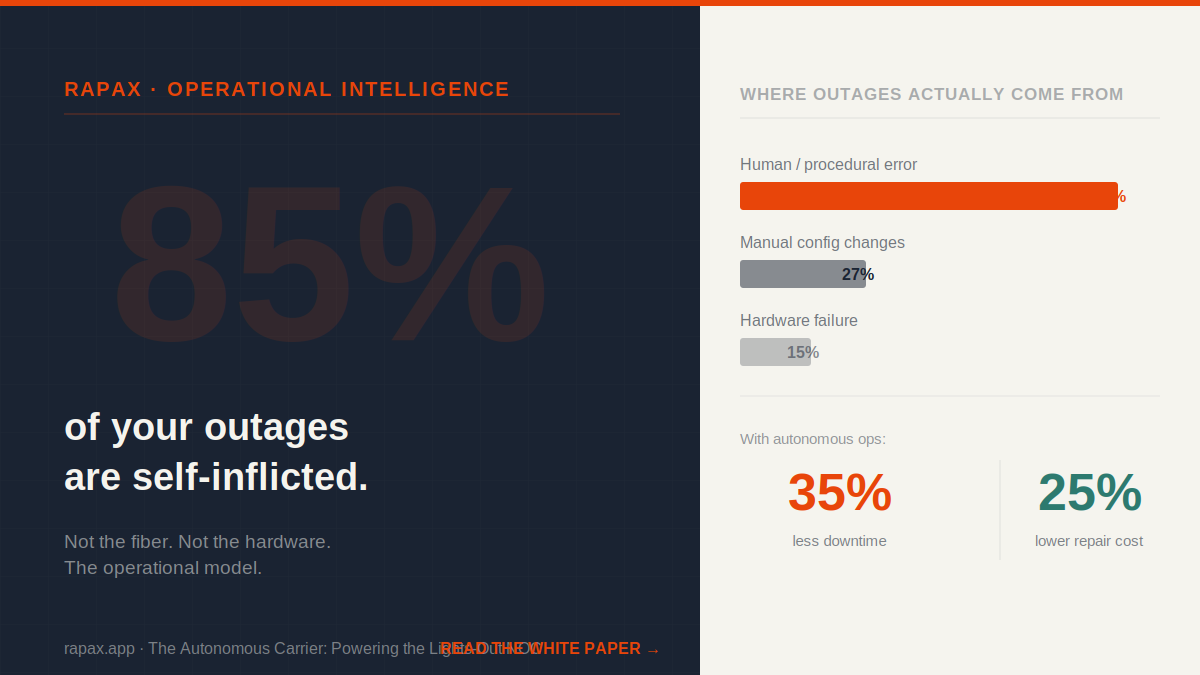
That number deserves a moment to land.
Not 85% of minor incidents. Not 85% of the low-severity events that close themselves in ten minutes. Eighty-five percent of human-error-related network outages — the ones that trigger bridge calls, SLA penalties, customer complaints, and emergency overtime — are caused by staff failing to follow or misinterpreting complex operational procedures.
The fiber cut gets the headline. The power failure gets the executive escalation. But when you look at the actual distribution of outage causes across a network over a twelve-month period, the leading cause is not the weather, not the hardware, and not the vendor. It is the operational model itself.
This is not an indictment of the people running these networks. It is an indictment of an architecture that puts humans in the critical path of complex, high-stakes, time-pressured decisions at a scale and frequency that will produce errors at a statistically predictable rate. The people are doing exactly what the model asks of them. The model is the problem.
The Configuration Error at the Center of Everything
Let me be specific about where the error rate concentrates, because it is not evenly distributed across operational tasks.
Industry analysis points to manual device configuration changes as the single largest driver of impactful outages — responsible for roughly 27% of all significant network downtime on their own. Not all human error. Just configuration changes specifically.
Think about what a configuration change looks like in a typical NOC environment. A change window is scheduled. A change request is approved through a multi-step process designed to catch errors before they reach production. A senior engineer executes the change — manually, through a CLI session, following a documented procedure that was written for a slightly different version of the platform than the one currently running in this specific environment. There is a verification step. The change is marked complete.
And somewhere in that chain — a wrong interface, a missed dependency, a procedure written for firmware version X applied to firmware version Y, a configuration that validated correctly in isolation and broke something three hops away — the error enters the network. Sometimes it surfaces immediately. Sometimes it creates a latent fault that triggers three weeks later under load conditions nobody anticipated.
The error is not random. It is the predictable output of complexity applied to humans under time pressure with imperfect documentation and heterogeneous infrastructure. You cannot procedure your way out of it. You cannot train your way out of it. The error rate for manual configuration management in complex environments has a floor, and it is not zero.
The Emergency Premium Nobody Is Tracking
Every one of those self-inflicted outages carries a cost that most carriers are not capturing as a single line item — because it is distributed across accounts that each look manageable in isolation.
There is the direct remediation cost: the engineering hours burned on root cause analysis, the emergency change window, the rollback procedure, the post-incident review. There is the SLA exposure: enterprise customers on service level agreements that carry financial penalties for downtime, penalties that compound quickly when a significant outage runs past the contractual threshold. There is the truck roll cost: the field dispatch triggered by a fault that could have been avoided or remotely remediated if the configuration had been correct in the first place. And there is the opportunity cost: the engineering capacity consumed by incident response that was scheduled for planned work — capacity that does not come back when the incident closes.
Gartner analysis puts early adopters of autonomous network operations at a 25% reduction in repair costs and a 35% drop in downtime. Those are not incremental improvements from tuning the existing model. They are the output of removing the human error surface area from the operational loop entirely.
Configuration Drift: The Slow Version of the Same Problem
The acute version of this problem is the outage that announces itself immediately. The chronic version is configuration drift — the gradual accumulation of manual changes, emergency workarounds, and undocumented modifications that move the network further from its intended state over time.
In a traditional NOC model, configuration drift is nearly invisible until it becomes a problem. Changes are made during incident response that do not make it back into the configuration management database. Workarounds applied during a maintenance window are not reversed when the underlying issue is resolved. Vendor firmware updates alter default behaviors that were previously overridden by explicit configuration — overrides that were not captured in any documentation the team can find.
The result is a network whose actual running state diverges incrementally from its documented state, week over week, until a future change or event triggers a failure mode that nobody can trace because nobody knows what the current baseline actually is.
An agentic security and compliance architecture treats configuration drift the way a good NOC treats a fault — as something to detect, alert on, and remediate before it becomes an outage. Agents continuously scan the running configuration against the policy baseline. When a drift event is detected — a manual change that violates security policy, a firmware update that altered a critical parameter, an undocumented modification that conflicts with a downstream dependency — the agent flags it, documents it, and where the remediation is deterministic, executes it automatically.
Cisco’s own research puts configuration automation at the top of the priority list for AI agent use cases in network operations — cited by 37% of network engineers as the highest-value application. That is not a coincidence. The people closest to the problem have already identified where the leverage is.
From Self-Inflicted to Self-Healing
The architectural shift that changes the 85% number is not more procedure. It is not more training. It is removing the human from the configuration execution path for the category of changes where human judgment adds no value that a well-grounded automation cannot provide.
That means autonomous configuration validation before a change reaches the network. It means continuous drift detection and policy enforcement after a change is made. It means an agentic response to fault events that correlates across layers — so when a fiber backhaul goes down, the response is not a ticket waiting for a human to triage, it is an immediate orchestrated action that reroutes traffic, adjusts wireless coverage, initiates field dispatch, and documents the event — all before the first bridge call is scheduled.
The carriers deploying this model are targeting a 30 to 40% reduction in total operational costs and a 40% decrease in outage frequency. The 85% error contribution does not go to zero — humans remain in the loop for the decisions that require human judgment. But the category of decisions that actually require human judgment is much narrower than the current operational model assumes. And every manual touchpoint you remove from the configuration path is a potential outage that never happens.
That is not an abstraction. It is a number on your incident report that does not appear this quarter.
The full architecture for the autonomous, self-healing network — including the Security and Compliance Agent, the Energy Agent, the unified wired-wireless convergence model, and the realistic 2027 targets — is in the white paper below.
Download: The Autonomous Carrier — Powering the Lights-Out NOC →
If any of this lands and you want to talk about what it means for your operation — 15 minutes at cal.com/shawn-ennis. No prep needed.
Leave a Reply