You know the call. Every VP of Operations and CTO in telecom knows the call.
It comes in on a Saturday morning, or at 2 a.m. on a Tuesday, or in the middle of a board presentation. The fiber is down. A node is unreachable. Alarms are cascading across the dashboard faster than anyone can read them. Someone starts a bridge line. Eight people join from whatever they were doing. The manual correlation begins.
Who saw it first? Which device is the parent fault? Is this a fiber cut or a power issue? Which customers are affected? Do we have an enterprise SLA on that segment? Has anyone notified the field team? What is the estimated time to restore?
Thirty minutes later, maybe sixty, you have answers to most of those questions. By then the customer has already called. The SLA clock has been running since the first alarm. The damage is done.
This is not a failure of the people on that bridge call. They are doing exactly what the operational model asks of them — sequentially, manually, as fast as human cognition allows. The problem is that human cognition is the bottleneck, and the bottleneck has a measurable cost every single time it engages.
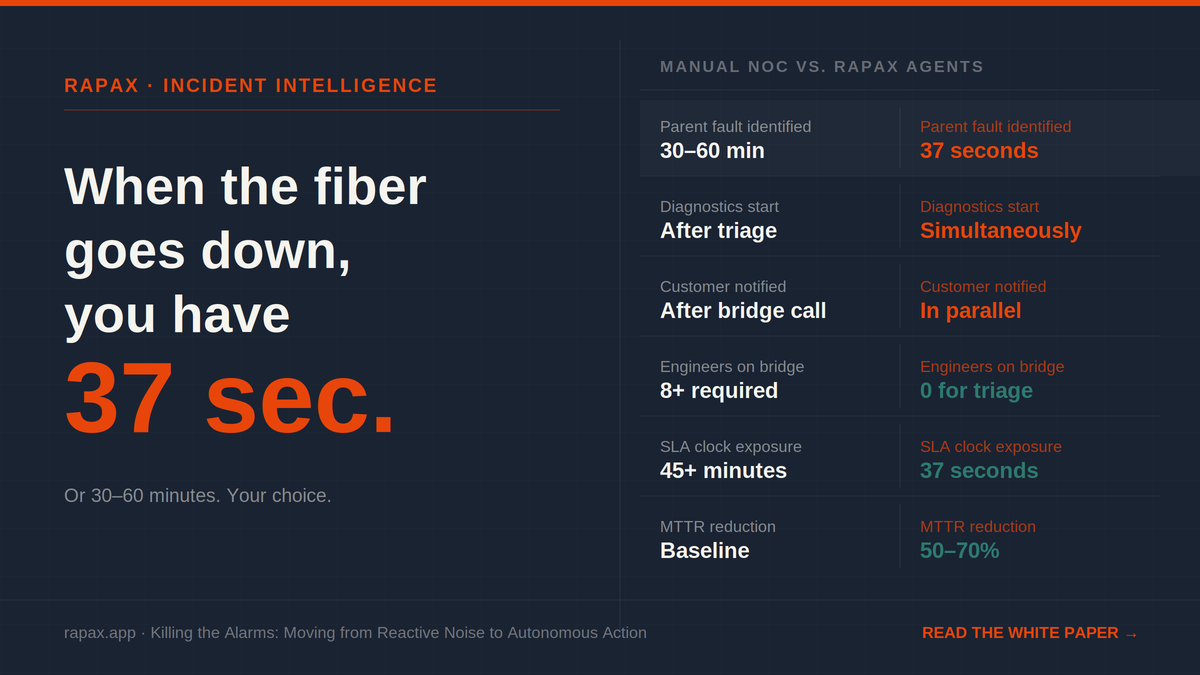
What 30–60 Minutes Actually Costs
Before I describe what 37 seconds looks like, it is worth being precise about what 30–60 minutes costs — because most carriers are not tracking it as a single line item.
There is the direct SLA exposure. Enterprise customers on carrier-grade service agreements carry financial penalty clauses that trigger on downtime thresholds. A 45-minute outage on a 99.99% SLA contract is a breach event. The penalty is written into the contract. It does not require a negotiation — it requires a credit memo.
There is the indirect customer impact. Consumer broadband customers do not call in as quickly as enterprise customers, but they notice. They check their phones. They try to stream. They fail. If your proactive communication system is manual — if someone has to compose and send a status notification after they have finished triaging the fault — those customers are sitting in silence for the duration of the bridge call.
There is the engineering cost. Eight people on a bridge call for 45 minutes is six hours of senior engineering time, fully loaded. That is six hours that were scheduled for something else. The backlog does not shrink because the bridge call happened — it grows.
And there is the compounding effect. The bridge call does not happen once. It happens every time a significant fault event occurs, across every shift, across every week of the year. The operational model that requires 30–60 minutes of manual correlation per major event will generate that cost as many times as major events occur. In a multi-vendor, multi-technology Tier 2 or Tier 3 network, that frequency is not low.
The 37-Second Alternative
Here is what happens in a Rapax-managed network when the same fiber cut occurs.
The fault event hits the network. Within milliseconds, the platform’s Hot Path — built on modern tech — ingests the streaming telemetry and delivers it to the agent layer. Victor, the Incident Controller, receives the event instantly.
Victor’s first task is parent fault identification — determining whether this alarm is a root cause or a downstream symptom of something else. In a manual NOC, this is the step that takes the longest. An engineer is looking at dozens of cascading alarms, trying to determine which one is the cause and which are the effects. Victor does this in seconds, not minutes, drawing on the full alarm stream and the network topology to identify the parent event unambiguously.
Victor then hands off in parallel. Wade, the Diagnostic Engine, begins executing hardware diagnostics and troubleshooting procedures on the affected segment — the Tier 2 technical work that under the traditional model waits for a senior engineer to finish the triage before it can start. Otto, the Network Engineer, understands the network change context and begins preparing recovery scripts for human-approved remote execution — so the moment a decision is made, execution is ready. Grace, the Alert Communications agent, is already composing and sending notifications to affected customers and stakeholders — not after the triage, not after the bridge call, but simultaneously with it.
Total elapsed time to root-cause identification: 37 seconds. Down from 30–60 minutes of manual alarm correlation.
The bridge call does not happen. The eight-person war room does not convene. The SLA clock runs for 37 seconds of autonomous triage instead of 45 minutes of human deliberation. The customer notification goes out before most of them have noticed anything is wrong.
Why the Sequential Model Cannot Close This Gap
The 37-second figure is not a product of faster hardware or a better alarm management interface. It is the product of parallel execution — four agents doing simultaneously what a human team does sequentially.
This is the structural advantage that no amount of tooling improvement delivers to a manual NOC. A better dashboard does not make alarm correlation faster if a human still has to read it. A better ticketing system does not reduce triage time if a human still has to populate it. The sequential model has a throughput ceiling that is defined by human cognitive speed, and that ceiling does not move regardless of what tools you put in front of it.
The agentic model has no such ceiling. Victor does not need to finish before Wade starts. Otto does not wait for Wade to finish before priming the recovery script. Grace does not wait for anyone — she begins stakeholder notification the moment Victor identifies the parent fault, because the information she needs is available immediately and the cost of delay is measurable in customer experience and NPS.
This is what the Lights-Out NOC actually means in practice. Not a NOC with the lights off because no one is there — a NOC where the work that used to require eight people on a bridge call for an hour is handled in 37 seconds by a coordinated agent fleet, and the humans are reviewing the outcome report instead of running the triage.
The Bridge Call You Stop Having
Every carrier I have worked with over 25 years has a version of the same institutional memory: the outage that lasted too long, the SLA breach that cost a major enterprise customer, the Saturday morning that consumed a team that had been planning something else. Those events are not anomalies. They are the predictable output of an operational model that puts human cognition in the critical path of time-sensitive, high-complexity decisions.
The 37-second number is not a benchmark target. It is a measured outcome from a running production deployment. The gap between that number and the 30–60 minutes your current model requires is not a gap that closes incrementally through process improvement. It closes when you remove the sequential human bottleneck from the triage path entirely.
The white paper below walks through the full architecture — how Victor, Wade, Otto, and Grace coordinate during a high-complexity event, what the data fabric underneath them looks like, and what the financial model for this transition actually is for a network carrier.
The bridge call is optional. The white paper explains why.
Download: Killing the Alarms — Moving from Reactive Noise to Autonomous Action →
If any of this lands and you want to talk about what it means for your operation — 15 minutes at cal.com/shawn-ennis. No prep needed.
Leave a Reply